Subsections of Features
Logging
2023 July 10
CrySPY 1.2.0 adopts logging library of Python.
CrySPY logs are output to both the screen and files(log_cryspy and err_cryspy).
- log –> screen and
log_cryspy - error and warning –> screen and
err_cryspy
Here is the example:
[2023-07-10 18:40:54,389][cryspy_init][INFO]
Start CrySPY 1.2.0
[2023-07-10 18:40:54,389][cryspy_init][INFO] # ---------- Read input file, cryspy.in
[2023-07-10 18:40:54,390][read_input][INFO] Save input data in cryspy.stat
[2023-07-10 18:40:54,391][cryspy_init][INFO] # ---------- Initial structure generation
[2023-07-10 18:40:54,391][cryspy_init][INFO] Number of MPI processes: 1
[2023-07-10 18:40:54,391][gen_init_struc][INFO] # ------ mindist
[2023-07-10 18:40:54,395][struc_util][INFO] Cu - Cu: 1.32
[2023-07-10 18:40:54,395][gen_init_struc][INFO] # ------ generate structures
[2023-07-10 18:40:54,481][gen_pyxtal][INFO] Structure ID 0 was generated. Space group: 1 --> 1 P1
[2023-07-10 18:40:54,493][gen_pyxtal][INFO] Structure ID 1 was generated. Space group: 28 --> 28 Pma2
[2023-07-10 18:40:54,498][gen_pyxtal][INFO] Structure ID 2 was generated. Space group: 29 --> 29 Pca2_1
[2023-07-10 18:40:54,704][gen_pyxtal][INFO] Structure ID 3 was generated. Space group: 137 --> 137 P4_2/nmc
[2023-07-10 18:40:54,725][gen_pyxtal][INFO] Structure ID 4 was generated. Space group: 212 --> 214 I4_132
[2023-07-10 18:40:54,800][cryspy_init][INFO] Elapsed time for structure generation: 0:00:00.408367
If you do not want output in the console, run cryspy with the -n option as follows:
cryspy -n
Backup
2024 Dec. 22 updated
CrySPY has a simple backup function. The following files are backed up:
- cryspy.in
- cryspy.stat
- log_cryspy
- err_cryspy
- debug_cryspy
- cryspy_interactive.ipynb
- calc_in/*
- data/*
work/* are NOT included.
- (v1.1.0 or later) above files are copied to a directory named by date and time in “backup” directory. Previous backups are NOT automatically deleted.
- (v1.0.0) only one generation is backed up, and previous backups will be deleted.
Auto backup
The timing of the automatic backup is as follows:
- before going to next selection (BO, LAQA) or next generation (EA)
- append structures
Manual backup
To manually back up, run cryspy with -b or --backup option as:
cryspy -b
This command only performs backups, unlike the normal execution.
Clean
2024 Dec. 22 updated
CrySPY has a simple clean (just move files) function. It is useful when you want to start over from the beginning. The following files are cleaned up:
- cryspy.stat
- log_cryspy
- err_cryspy
- lock_cryspy
- data/*
- work/*
- tmp_gen_struc/*
To clean up, run cryspy with -c or --clean option as:
$ ls
calc_in cryspy.in cryspy.stat data err_cryspy log_cryspy
$ cryspy -c
Are you sure you want to clean the data? 'yes' or 'no' [y/n]: y
$ ls
calc_in cryspy.in trash
$ ls trash
20230318_100728
Files other than calc_in/* and cryspy.in are moved to trash and grouped into a directory named by date and time.
If you do not need them, you can delete them manually.
Restriction on interatomic distances
2024 April 23, updated
You can restrict the interatomic distance in structure generation. Here is an example of [structure] section in the input file to limit minimum interatomic distance for a A-B binary system.
[structure]
natot = 8
atype = A B
nat = 4 4
mindist_1 = 2.0 1.8
mindist_2 = 1.8 1.5
This means that minimum interatomic distances of A-A, A-B, and B-B are limited to 2.0, 1.8, and 1.5 Å, respectively. Structures with interatomic distances shorter than these values are automatically eliminated.
For ternary systems, you will need mindist_1, mindist_2, and mindist_3.
Mindist matrix must be a symmetric matrix.
Since CrySPY version 1.4.0, the minimum interatomic distance check is also performed after structure relaxation.
This feature was introduced because, with machine learning potentials, structures with nearly overlapping atoms can sometimes be obtained.
You can disable this feature by adding the following line to cryspy.in (it is enabled by default):
[option]
check_mindist_opt = False
Example: Na8Cl8
Without mindist
cryspy.in
[basic]
algo = RS
calc_code = VASP
tot_struc = 5
nstage = 2
njob = 2
jobcmd = qsub
jobfile = job_cryspy
[structure]
natot = 16
atype = Na Cl
nat = 8 8
[VASP]
kppvol = 40 80
[option]
log_cryspy
[2024-04-23 13:46:28,598][cryspy_init][INFO]
Start CrySPY 1.2.3
[2024-04-23 13:46:28,598][cryspy_init][INFO] # ---------- Read input file, cryspy.in
[2024-04-23 13:46:28,598][read_input][INFO] Save input data in cryspy.stat
[2024-04-23 13:46:28,599][gen_init_struc][INFO] # ------ mindist
[2024-04-23 13:46:28,601][struc_util][INFO] Na - Na: 1.66
[2024-04-23 13:46:28,602][struc_util][INFO] Na - Cl: 1.3399999999999999
[2024-04-23 13:46:28,602][struc_util][INFO] Cl - Cl: 1.02
...
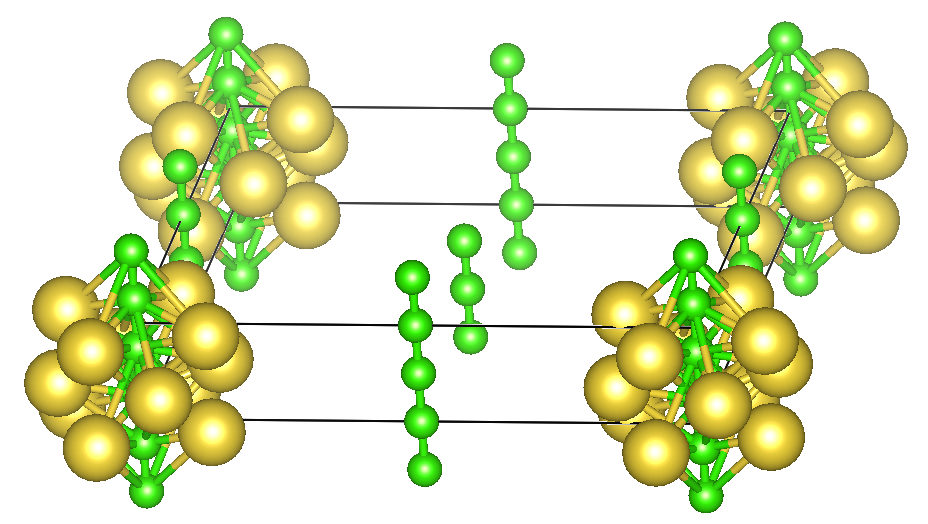
In the default settings of PyXtal, atoms can sometimes be too close to each other, as shown in the figure above, so it is recommended to set the mindist parameter. That would help simplify DFT calculations.
With mindist
cryspy.in
[basic]
algo = RS
calc_code = VASP
tot_struc = 5
nstage = 2
njob = 2
jobcmd = qsub
jobfile = job_cryspy
[structure]
natot = 16
atype = Na Cl
nat = 8 8
mindist_1 = 2.5 1.5
mindist_2 = 1.5 2.5
[VASP]
kppvol = 40 80
[option]
log_cryspy
[2024-04-23 14:06:21,955][cryspy_init][INFO]
Start CrySPY 1.2.3
[2024-04-23 14:06:21,955][cryspy_init][INFO] # ---------- Read input file, cryspy.in
[2024-04-23 14:06:21,956][read_input][INFO] Save input data in cryspy.stat
[2024-04-23 14:06:21,956][gen_init_struc][INFO] # ------ mindist
[2024-04-23 14:06:21,956][struc_util][INFO] Na - Na: 2.5
[2024-04-23 14:06:21,956][struc_util][INFO] Na - Cl: 1.5
[2024-04-23 14:06:21,956][struc_util][INFO] Cl - Cl: 2.5
In cases like ionic crystals, it is advisable to set up the configuration in such a way that cations and anions are kept apart from each other.
Job file auto-rewriting
2025 July 10, updated
In CrySPY job files, the string CrySPY_ID is automatically replaced with the structure ID.
When using job schedulers like PBS or SLURM, it is convenient to use the structure ID in the job name.
For example, in PBS, #PBS -N Si_CrySPY_ID becomes #PBS -N Si_15.
In most cases, job names cannot start with numbers, so it’s good to start with letters like Si_.
Also, since version 1.4.2, it is no longer necessary to write the following command at the end. CrySPY automatically appends it.
sed -i -e '3s/^sub.*/done/' stat_job
For example, if you prepare a job file like this in ./calc_in/job_cryspy (where job_cryspy is the file name specified by jobfile in cryspy.in):
#!/bin/sh
#$ -cwd
#$ -V -S /bin/bash
####$ -V -S /bin/zsh
#$ -N Si8_CrySPY_ID
#$ -pe smp 20
####$ -q ibis1.q
####$ -q ibis2.q
mpirun -np $NSLOTS pw.x < pwscf.in > pwscf.out
if [ -e "CRASH" ]; then
sed -i -e '3 s/^.*$/skip/' stat_job
exit 1
fi
For example, if the ID is 15, CrySPY rewrites ./work/15/job_cryspy as follows.
The CrySPY_ID in the 5th line is replaced with 15, and the sed command is appended at the end.
#!/bin/sh
#$ -cwd
#$ -V -S /bin/bash
####$ -V -S /bin/zsh
#$ -N Si8_15
#$ -pe smp 20
####$ -q ibis1.q
####$ -q ibis2.q
mpirun -np $NSLOTS pw.x < pwscf.in > pwscf.out
if [ -e "CRASH" ]; then
sed -i -e '3 s/^.*$/skip/' stat_job
exit 1
fi
# ---------- CrySPY
sed -i -e '3s/^sub.*/done/' stat_job
Structure generation with MPI parallelization
Oct. 21 2023, update
Random structure generation using MPI has been available since version 1.1.0 ( using CrySPY >= 1.2.3 is better). You need to install mpi4py in your Python environment for MPI parallelization. Of course, an MPI library such as Open MPI, Intel MPI, and MPICH is required for your workstation.
Info
Requirements:
- CrySPY
1.1.01.2.3 or later - mpi4py
- MPI library (Open MPI, Intel MPI, MPICH, etc.)
Warning
1.1.0 <= CrySPY <=1.2.2 has a bug.
When you use bash (zsh) to run a job with MPI (e.g., jobcmd = zsh, jobfile = job_cryspy),
the MPI job does not run. There is no problem when you use a job scheduler (qsub, sbatch).
It has already fixed in version 1.2.3.
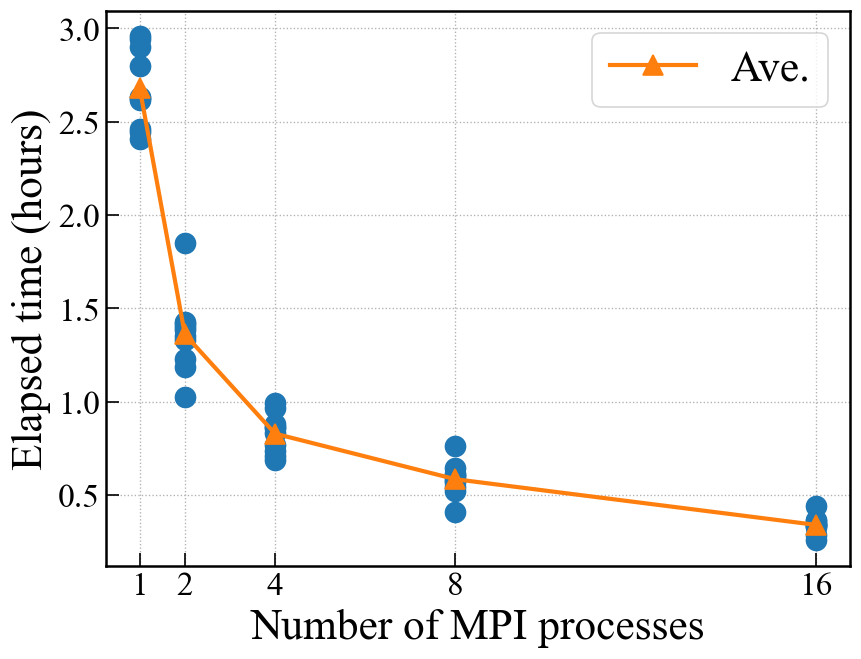
The figure below shows the relationship between elapsed time and the number of processes for 1000 structures of Si8 with the following setting:
[basic]
algo = RS
calc_code = soiap
tot_struc = 1000
nstage = 1
njob = 2
jobcmd = zsh
jobfile = job_cryspy
[structure]
natot = 8
atype = Si
nat = 8
mindist_1 = 2.2
The structure generation is taking a long time because of a slightly stricter setting like mindset_1 = 2.2.
The structure generation was performed 10 times for each number of processes.
Run
mpiexec -n 4 cryspy -p
Info
Enthalpy
2023/10/18
Info
Requirements:
- CrySPY 1.2.2 or later
- VASP or QE
When performing CSP at high pressure, enthalpy results can be collected instead of total energy. Not yet compatible with softwares other than VASP and QE.
E_eV_atom in cryspy_rslt and cryspy_rslt_energy_asc turns into enthalpy (eV/atom). Here is the example of CSP results under 40 GPa pressure for Sr4O4.
CsCl-type structure (ID 5) is more stable than NaCl-type (ID 6).
Spg_num Spg_sym Spg_num_opt Spg_sym_opt E_eV_atom Magmom Opt
5 26 Pmc2_1 221 Pm-3m -2.276790 NaN done
6 225 Fm-3m 225 Fm-3m -2.244800 NaN done
1 101 P4_2cm 107 I4mm -2.181115 NaN done
4 123 P4/mmm 123 P4/mmm -2.034509 NaN not_yet
3 20 C222_1 63 Cmcm -0.686541 NaN done
2 75 P4 75 P4 -0.008713 NaN not_yet
9 51 Pmma 47 Pmmm 0.096430 NaN done
8 65 Cmmm 123 P4/mmm 1.099657 NaN done
0 187 P-6m2 187 P-6m2 1.292124 NaN done
7 53 Pmna 53 Pmna 5.153504 NaN not_yet
VASP
CrySPY reads energy (enthalpy) from a OSZICAR file.
This automatically changes to enthalpy when PSTRESS is set in INCAR_x as follows:
PSTRESS = 400
You do not have to do anything in cryspy.in.
energy_step_flag is also supported for enthalpy.
Example: CrySPY utility > examples > qe_Sr4O4_RS_pv_term
QE
Add pv_term = True in the QE section of cryspy.in to use enthalpy:
[QE]
qe_infile = pwscf.in
qe_outfile = pwscf.out
kppvol = 40 80
pv_term = True
Don’t forget to write press in the QE input:
&cell
press = 400
/
Warning
In QE, energy_step_flag is not supported yet for enthalpy.
As library
2024 May 31
Info
Requirements:
- CrySPY 1.3.0 or later
Cryspy can be used as a library to generate random structures or structures by evolutionary algoritym. The jupyter notebook is available in CrySPY utility > notebook > as_library.
Random structure generation
####
#### when you change set_logger(), you need to restart the kernel
####
from cryspy.util.utility import set_logger # optional
set_logger() # optional
#set_logger(noprint=True, logfile='log_cryspy', errfile='err_cryspy') # write log and err messages to files
from cryspy.RS.gen_struc_RS import gen_pyxtal
nstruc = 10
atype = ('Na', 'Cl')
nat = (4, 4)
mindist = ((2.0, 1.5),
(1.5, 2.0))
spgnum = 'all'
init_struc_data = gen_pyxtal.gen_struc(
nstruc=nstruc,
atype=atype,
nat=nat,
mindist=mindist,
spgnum=spgnum,
)
You can get init_struc_data (dict: {ID: pymatgen Strcture, …})
Structure generation by evolutionary algorithm
Situation: parent A (, parent B) –> child
Prepare two (one) parent structures as pymatgen Structure object.
In this example, just use the results of RS for Cu4Au4 (see, CrySPY utility > notebook > as_library).
import pickle
with open('./Cu4Au4_sample/opt_struc_data.pkl', 'rb') as f:
opt_struc_data = pickle.load(f)
Crossover
from cryspy.EA.gen_struc_EA import crossover
# you can change parent_A and parent_B
parent_A = opt_struc_data[0]
parent_B = opt_struc_data[1]
atype = ('Cu', 'Au')
nat = (4, 4)
mindist = ((1.5, 1.5),
(1.5, 1.5))
child = crossover.gen_child(
atype=atype,
nat=nat,
mindist=mindist,
parent_A=parent_A,
parent_B=parent_B,
)
# child: pymatgen Structure
Permutation
from cryspy.EA.gen_struc_EA import permutation
# you can change parent_A
parent_A = opt_struc_data[0]
atype = ('Cu', 'Au')
nat = (4, 4)
mindist = ((1.5, 1.5),
(1.5, 1.5))
ntimes = 1 # number of times to perform permutatio
child = permutation.gen_child(
atype=atype,
mindist=mindist,
parent_A=parent_A,
ntimes=ntimes,
)
# child: pymatgen Structure
Strain
from cryspy.EA.gen_struc_EA import strain
atype = ('Cu', 'Au')
nat = (4, 4)
mindist = ((1.5, 1.5),
(1.5, 1.5))
sigma_st = 0.05 # standard deviation of strain
child = strain.gen_child(
atype=atype,
mindist=mindist,
parent_A=parent_A,
sigma_st=sigma_st,
)
Situation: parent group, fitness –> children
Data set
Prepare structure and fitness (energy) data as dict. The key is structure ID. In this example, just use the results of RS for Cu4Au4 (see, CrySPY utility > notebook > as_library)..
e.g.
struc_data = {0: (pymatgen Structure), 1: (pymatgen Structure), …}
fitness = {0: 0.019632287242441926, 1: -0.005437509701440302, …}
import pickle
with open('./Cu4Au4_sample/opt_struc_data.pkl', 'rb') as f:
opt_struc_data = pickle.load(f)
with open('./Cu4Au4_sample/rslt_data.pkl', 'rb') as f:
rslt_data = pickle.load(f)
struc_data = opt_struc_data # dict
fitness = rslt_data['E_eV_atom'].to_dict() # you may include None or np.nan for values
Survival of the fittest
from cryspy.EA.survival import survival_fittest
from cryspy.EA.gen_struc_EA.select_parents import SelectParents
from cryspy.EA.gen_struc_EA import crossover, permutation, strain
n_fittest = 5 # number of survivors
ranking, _, _ = survival_fittest(
fitness=fitness,
struc_data=struc_data,
elite_struc=None,
elite_fitness=None,
n_fittest=n_fittest,
fit_reverse=False,
emax_ea=None,
emin_ea=None,
)
# ranking <-- e.g. [2, 1, 0, 7, 9] without structure duplicaiton
Select parents class
sp = SelectParents(ranking) # after set_xxx, we can use sp.get_parents(n_parent)
sp.set_tournament(t_size=2)
Crossover
atype = ('Cu', 'Au')
nat = (4, 4)
mindist = ((1.5, 1.5),
(1.5, 1.5))
n_crsov = 5 # number of structures to be generated by crossover
#id_start = len(init_struc_data) # next Structure ID
id_start = 10
co_children, co_parents, co_operation = crossover.gen_crossover(
atype=atype,
nat=nat,
mindist=mindist,
struc_data=struc_data,
sp=sp,
n_crsov=n_crsov,
id_start=id_start,
)
# co_children <-- dict {ID: pymatgen Structure, ID: pymatgen Structure, ...}
# co_parents <-- e.g. {10: (2, 7), 11: (2, 1), 12: (2, 1), 13: (0, 2), 14: (2, 1)}
# co_operation <-- e.g. {10: 'crossover', 11: 'crossover', ...}
Permutation
n_perm = 5 # number of structures to be generated by permutation
#id_start = len(init_struc_data) + n_crsov # next Structure ID
id_start = 15
ntimes = 1 # number of times to perform permutation
pm_children, pm_parents, pm_operation = permutation.gen_permutation(
atype=atype,
mindist=mindist,
struc_data=struc_data,
sp=sp,
n_perm=n_perm,
id_start=id_start,
ntimes=ntimes,
)
# pm_children <-- dict {ID: pymatgen Structure, ID: pymatgen Structure, ...}
# pm_parents <-- e.g. {15: (2,), 16: (1,), 17: (2,), 18: (1,), 19: (1,)}
# pm_operation <-- e.g. {15: 'permutaion', 16: 'permutation', ...}
Strain
n_strain = 5 # number of structures to be generated by strain
#id_start = len(init_struc_data) + n_crsov + n_perm # next Structure ID
id_start = 20
sigma_st = 0.05 # standard deviation of strain
st_children, st_parents, st_operation = strain.gen_strain(
atype=atype,
mindist=mindist,
struc_data=struc_data,
sp=sp,
n_strain=n_strain,
id_start=id_start,
sigma_st=sigma_st,
)
# st_children <-- dict {ID: pymatgen Structure, ID: pymatgen Structure, ...}
# st_parents <-- e.g. {20: (1,), 21: (2,), 22: (0,), 23: (2,), 24: (2,)}
# st_operation <-- e.g. {20: 'strain', 21: 'strain', ...}
Interactive mode
2025 March 6
Info
An interactive mode using Jupyter Notebook has been made available to ensure ease of use, even for those unfamiliar with PC clusters or supercomputers. Since the structure optimization calculations are designed for ASE, compatible machine learning potentials can be used.
For detailed usage, please refer to Tutorial > Interactice mode(Jupyter Notebook).
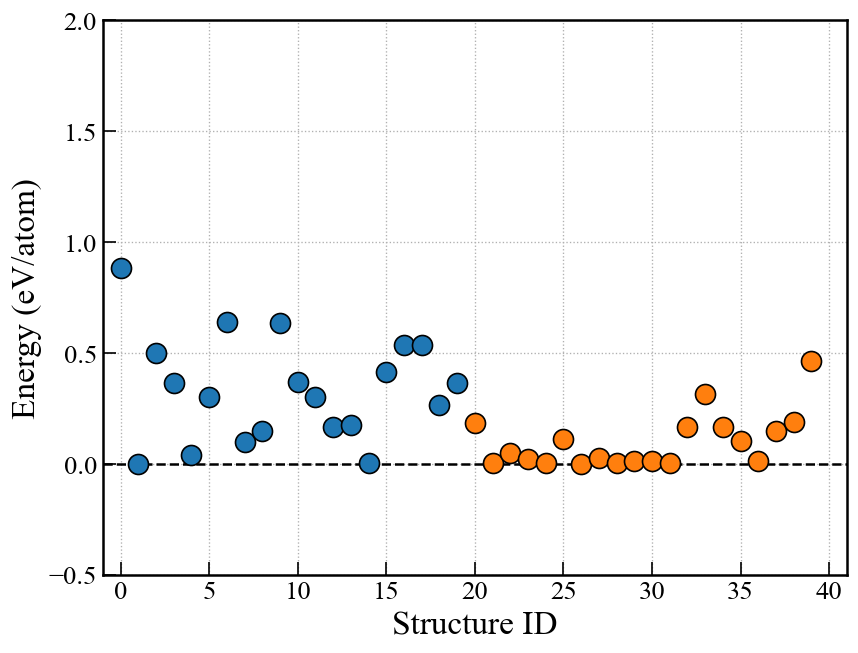
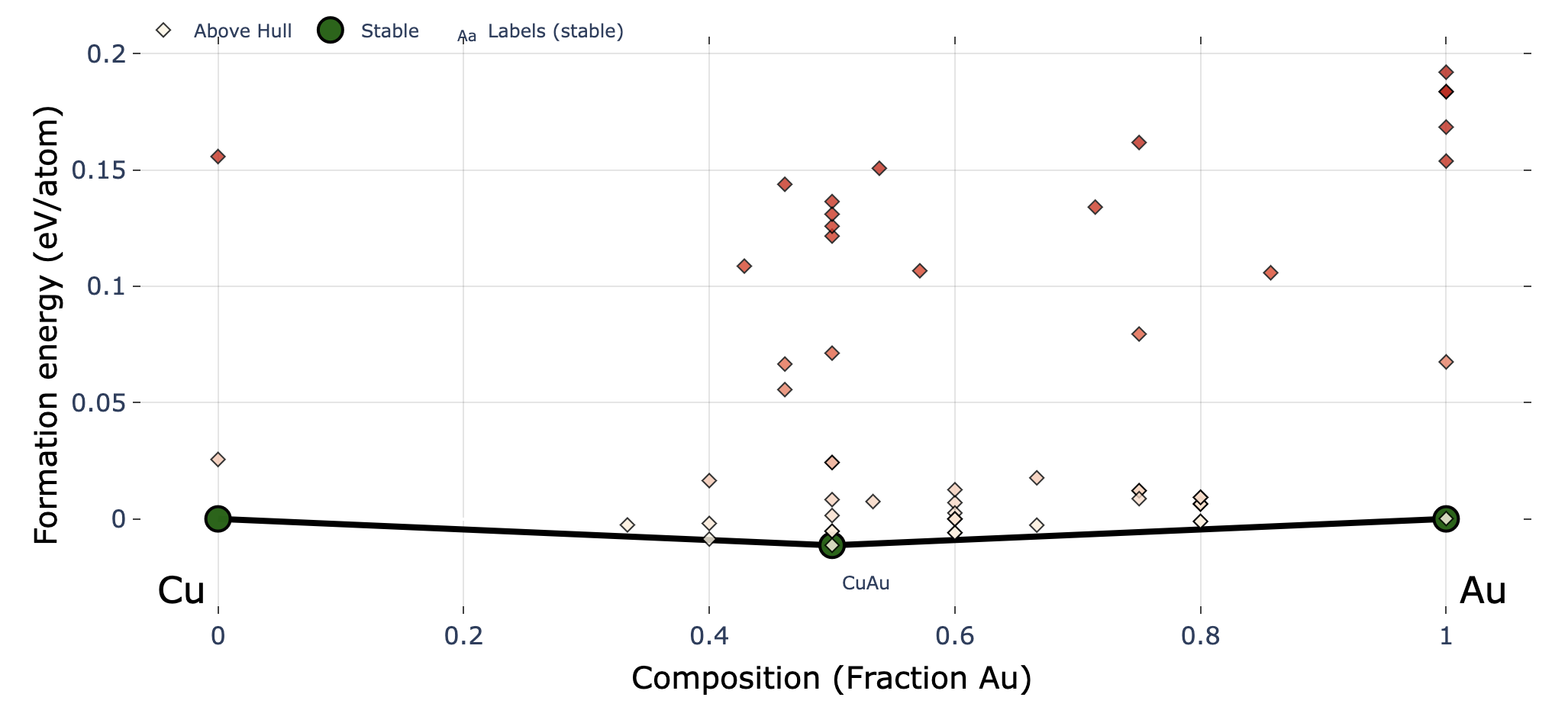
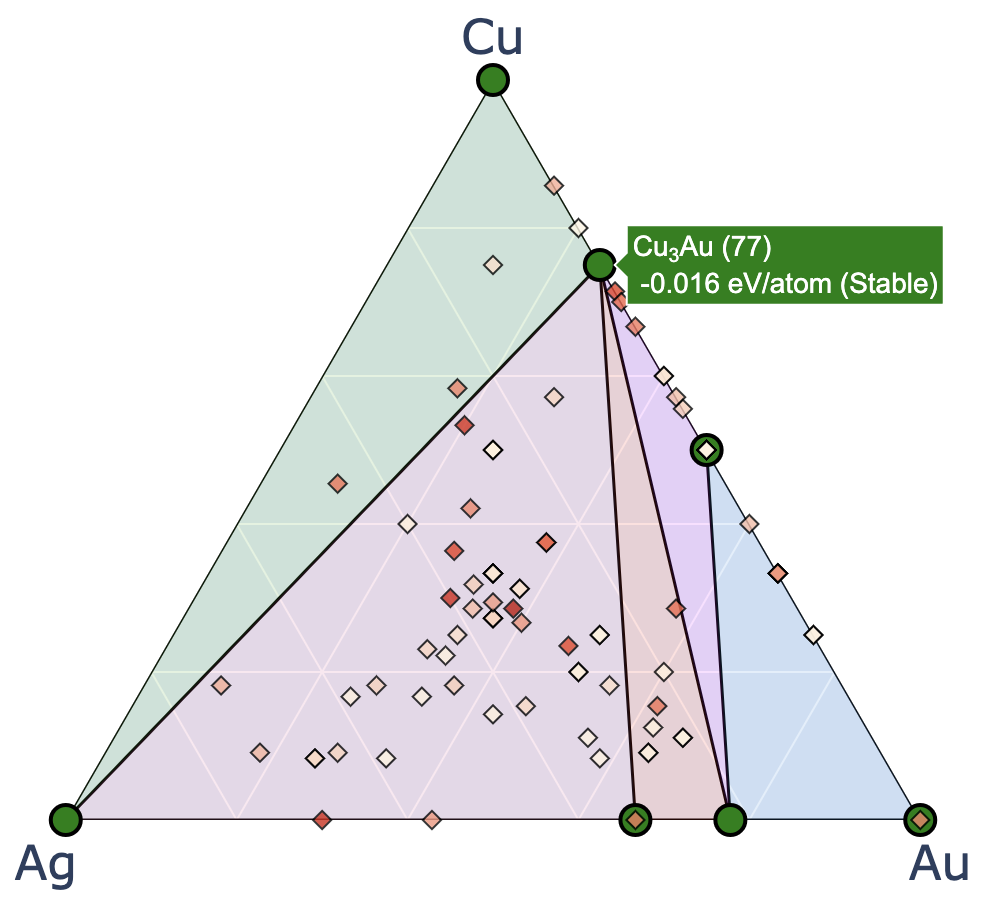
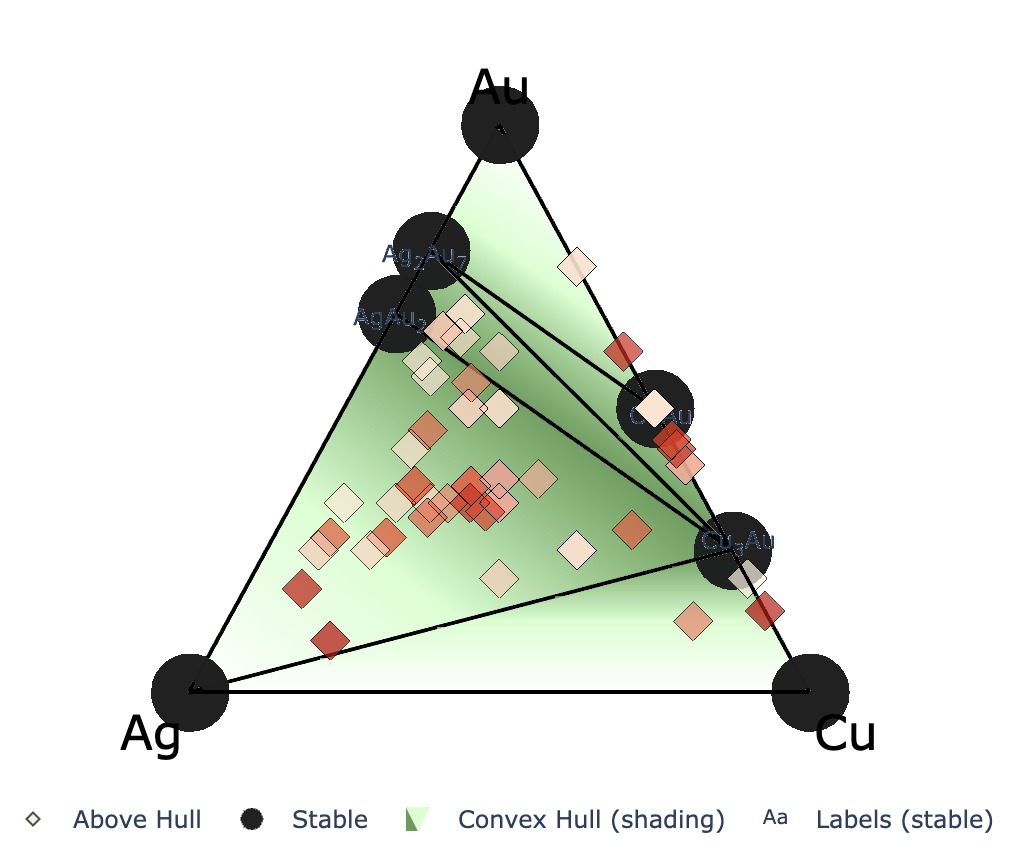
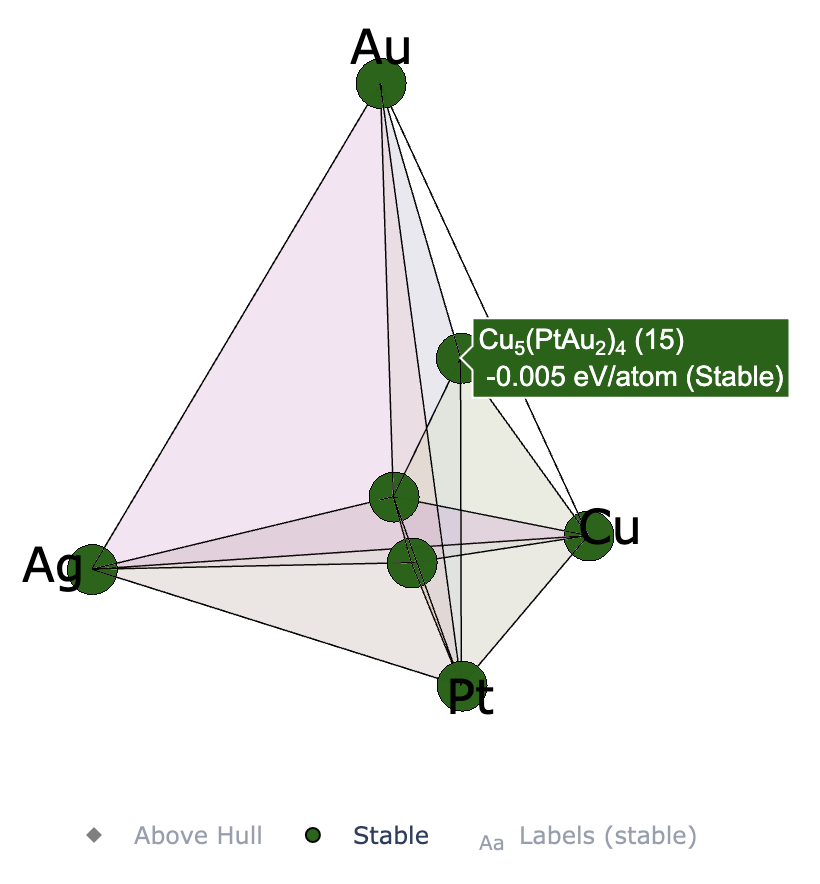
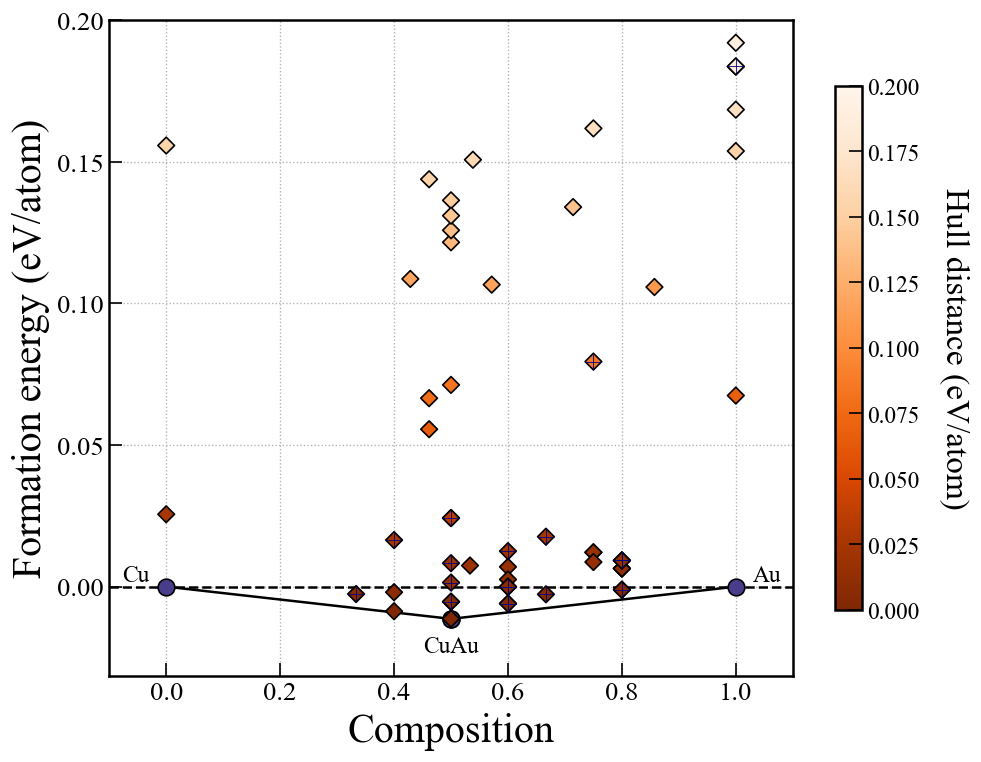
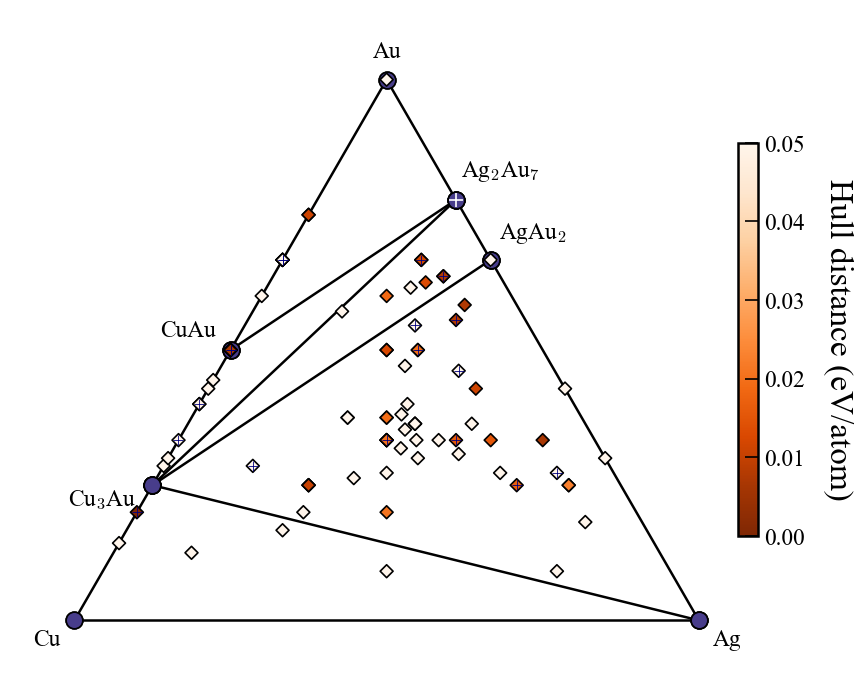
Re-plot convex hull
2025 July 3
Starting from CrySPY version 1.4.1, the cryspy-Eplot command is installed.
In EA-vc, a convex hull plot is automatically generated and saved at the end of each generation’s calculation.
If you wish to adjust the plotting parameters afterward, you can re-plot the graph using the cryspy-Eplot command.
Usage
Modify the following parameters directly in the [EA] section of cryspy.in, and then run cryspy-Eplot.
- cgen
- show_max
- label_stable
- vmax
- bottom_margin
- fig_format
cgen specifies the maximum generation number included in the plot.
The default is None, meaning up to the latest generation.
In EA-vc, the convex hull is computed at the end of each generation, So specifying an unfinished generation with cgen may result in an error.
The output image file will be overwritten at ./data/convex_hull/conv_hull_gen_{cgen}.{fig_format}.
For details on other parameters, refer to CrySPY > Tutorial > EA-vc > Analysis and visualization.
Charge neutrality condition
July 5, 2025
From version 1.4.1, it is possible to impose a charge neutrality condition during structure generation in EA-vc. This can be applied to both random structure generation and structure generation by evolutionary operations.
In cryspy.in, the charge corresponding to each atype is specified as charge.
Example of cryspy.in:
...
[structure]
atype = Li Ca Cl
ll_nat = 0 0 0
ul_nat = 8 8 8
charge = 1 2 -1
...
For example, in this case, only structures that satisfy the charge neutrality condition, such as (Li, Ca, Cl) = (4, 0, 4) or (Li, Ca, Cl) = (4, 2, 8), will be generated.
Note that if add_max or elim_max is too small as shown below, there may be no combinations of atom numbers that satisfy the charge neutrality condition when adding or removing atoms, making structure generation impossible.
...
[structure]
atype = Li Ca Cl
ll_nat = 0 0 0
ul_nat = 8 8 8
charge = 1 2 -1
...
...
[EA]
add_max = 1
elim_max = 1
For example, in the above case, if add_max = 1, there are no combinations of atom numbers that satisfy the charge neutrality condition. If add_max = 2, (Li, Ca, Cl) = (1, 0, 1), that is, adding one Li and one Cl atom, satisfies the charge neutrality condition because (+1) + (-1) = 0. If add_max = 3, there are combinations such as (Li, Ca, Cl) = (1, 0, 1) and (0, 1, 2).
Skip calculations
2025 July 15
Skip during calculation
When electronic states in DFT calculations fail to converge or when you want to stop calculations for obviously unstable structures, you can skip them using the following procedure:
- Stop the job using
qdelor similar command - Change the 3rd line of
./work/xxx/stat_jobtoskip - Run CrySPY as usual
This will discard the structure and proceed to the next calculation.
Skip after recording in cryspy_rslt (rslt_data.pkl)
CrySPY version 1.4.2 or later
When calculations finish with incorrect electronic states, the energy may be output excessively low and recorded in rslt_data. For example, in the following result, the energy of ID 198 is too low:
cryspy_rslt_energy_asc
Gen ... E_eV_atom Ef_eV_atom ...
198 10 ... -5.542899 -1.800631 ...
157 8 ... -5.598984 -0.356639 ...
186 10 ... -6.323099 -0.330717 ...
95 5 ... -6.317931 -0.325549 ...
To cancel this data and skip it, use the command automatically installed from version 1.4.2:
cryspy-skip 198
If you want to skip multiple structures, input multiple IDs:
cryspy-skip 198 157
This will update the data.
For EA or EA-vc
In the case of EA or EA-vc, the structure to be skipped may be registered as an elite structure. Using the cryspy-skip command removes the structures to be skipped from the data stored in elite_struc.pkl and elite_fitness.pkl.
Recalculating convex hull for EA-vc
In the case of EA-vc, the energy of the structure to be skipped may affect the convex hull calculation. Therefore, after skipping, recalculate the convex hull using the following command:
cryspy-calc-convex-hull 10
The 10 in the above input represents the generation, and it recalculates and plots the convex hull at generation 10.