探索アルゴリズムのサブセクション
Random search (RS)
under construction
進化的アルゴリズム (EA)
2025 April 2
背景
進化的アルゴリズム(EA)は,進化論に着想を得たメタヒューリスティックな手法である. EA は,これまでに探索された安定構造(親構造)の局所環境を受け継ぐことで,新たな構造(子個体)を効果的に生成することができる. Oganov グループの USPEX はよく知られたソフトウェアであり,そのほかにも XtalOpt などがある. 先行研究の例は以下の通り.
- T. S. Bush, C. R. A. Catlow, and P. D. Battle, J. Mater. Chem. 5, 1269 (1995).
- A. R. Oganov and C. W. Glass, J. Chem. Phys. 124, 244704 (2006).
- A. R. Oganov, A. O. Lyakhov, and M. Valle, Acc. Chem. Res. 44, 227 (2011).
- A. O. Lyakhov, A. R. Oganov, H. T. Stokes, and Q. Zhu, Comput. Phys. Commun. 184, 1172 (2013).

手順
- 個体群(population)の初期化
- 適応度(fitness)の評価
- 自然選択
- 親個体の選択
- 次世代の生成
- ステップ2(適応度の評価)に戻り繰り返す
個体群(population)の初期化
第一世代では,n_pop で指定された数のランダム構造が生成される.
EAおよびEA-vcにおいては,tot_struc は使用されない.
適応度(fitness)の評価
現在,CrySPYにおいて適応度として使用できるのはエネルギーのみである.
fit_reverse = False に設定することで,最小値探索モードになるよう構成されている.
この fit_reverse の設定は,将来的にエネルギー以外の物性を適応度として用いる場合に備えて用意されている.
自然選択
DFT計算では,まれに失敗して極端に不合理なエネルギー値が得られることがある.
emax_ea および emin_ea を用いることで,極端に高い(または低い)エネルギーを持つ構造を除外することができる:
$$ \mathrm{emin\_ea} \le E \ (\mathrm{eV/atom}) \le \mathrm{emax\_ea} $$
たとえば,emin_ea を設定すると,その値よりも低いエネルギーを持つ構造は無視される.
自然選択では,まず現在の個体群と,過去の世代から保持されたエリート個体が,適応度に基づいてランク付けされる.
ここで使用されるエリート個体の数は,n_eliteで指定される.
現在の個体群とエリート個体の中から,適応度の高い順に n_fittestの数の個体が選択され,それ以外は淘汰される.
自然選択の過程では,pymatgen のStructureMatcher クラスにより重複を除去し,上位n_fittestの数の個体を選択している.
n_fittest は,n_pop(個体群サイズ)の約半分に設定されることが多い.
現在の実装では,n_fittest = 0 の場合,すべての個体が保持される仕様になっている.
下の図はn_fittest = 5の場合の自然選択の例を示している.

親個体の選択
親候補の個体の中から1つの親個体を選択するために,CrySPYでは2種類の選択手法が実装されている.
いずれの手法も,適応度の高い個体がより高い確率で選ばれるように設計されている.
slct_func = TNMを設定するとトーナメント選択が,slct_func = RLTを設定するとルーレット選択が使用される.
トーナメント選択はパラメータが少なく,簡単に使用できる点が利点である.
次世代の生成
次世代は,親候補の個体に対して進化的操作を適用して生成された子個体と,一部のランダム構造から構成される. ランダム構造は,多様性を維持し,局所的最小からの脱出を促すために各世代で追加される.
進化的操作
ここでは,CrySPYに実装されている,組成固定型EAの進化的操作を紹介する.
個体群の数
crossover, permutation, strainおよびランダムに生成された構造数の合計がn_popと等しくなければならない.
n_pop=n_crsov+n_perm+n_strain+n_rand
進化的アルゴリズム (EA)のサブセクション
Crossover
概要
交叉(cross over)は,2つの親構造のスライスされた領域を交換することで,新たな構造(子個体)を生成する進化的操作である. この操作により,構造の多様性が促進され,局所的に安定な特徴が遺伝することが可能となる. 構造探索において低エネルギー構造を効率的に探索するための主要な手法のひとつである.
手順
- 親候補から異なる個体を2つ選択
- ランダムに並進操作
- 格子ベクトルをランダムに選択
- 中央付近で親構造を切断
- 切断された半分を交換
- 原子数の多い子構造を選択
- ボーダー付近で原子数の調整
- 最小原子間距離のチェック

4. 中央付近で親構造を切断
切断ポイントは中央付近で,下記のように毎回少し変化させる.
slice_point = np.clip(np.random.normal(loc=0.5, scale=0.1), 0.3, 0.7)
以降のステップで失敗した場合,このステップ4に戻って再開する場合がある.
ただし,再開可能な回数はmaxcnt_eaで上限が決められており,それを過ぎた場合は親の選択からやり直す.
5. 切断された半分を交換
crs_latがrandomの時,子構造の格子ベクトルは2つの親構造のうちのどちらか一方をそのまま引き継ぐ.
crs_latがequalの場合は,親構造の格子ベクトルの平均を使う.
デフォルトはrandom.
6. 原子数の多い子構造を選択
親構造を入れ替えると,通常二つの原子数の異なる構造が得られる. とりあえず,原子数の多い構造を採用する.

ただし,原子数が元の構造のものと大きく違う場合はステップ4(中央付近で親構造を切断)からやり直す.
その許容量はnat_diff_toleで決める.
デフォルト値は4で,その場合それぞれの元素において原子数の差が±4まで許容される.
上の図の場合,元の構造と比較すると,青の原子は-1で,緑の原子は+2になっている.
7. ボーダー付近で原子数の調整
削除
原子数を調整する際,まずは原子の削除から行う.
下の図に示すように,mindistで定義される最小原子間距離を満たしていない原子から優先的に削除される.

以下のように,もし原子の削除が完了しても最小原子間距離の制限にかかる原子がある場合,ステップ4(中央付近で親構造を切断)からやり直す.

最小原子間距離の制限にかかる原子が無く,さらに原子を削除する必要がある場合は,下の図に示すようにボーダーから近い原子から削除する.切断ポイントに加えて内部座標が0のところもボーダーであることに注意.

追加
原子が不足しているときは,その原子をボーダー付近に追加する. 選択されている軸に沿った内部座標は下記のように決める. ここでmeanは切断ポイントの座標か0である.
coords[axis] = np.random.normal(loc=mean, scale=0.08)
座標の残りの二つの成分はランダムに決められる. 最小原子間距離のチェックを行いながら,元の組成と一致するまで原子を追加する.

Permutation
概要
置換(permutation)は,単一の構造内における異なる元素同士の配置を入れ替えることで,新たな構造(子個体)を生成する進化的操作である. この操作により,格子および全体の組成を変えることなく,異なる構造配置の探索が可能となる.
手順
異なる元素の原子の位置を入れ替える.
原子の入れ替えの回数はntimesで指定する.デフォルトは1回.
入れ替え後,最小原子間距離をチェックする.

Strain
概要
歪み(strain)は,親構造の格子に対して小さなランダムな変形を加えることで,新たな構造(子個体)を生成する進化的操作である. この操作により,原子の接続関係や組成を保持しつつ,構造空間の近傍領域を探索することが可能となる. 構造候補の微調整や,局所的な最小値からの脱出にも有効である.
手順
以下の歪み行列を用いて,格子ベクトル $ \mathbf{a} $を変形させる.
$$ \mathbf{a}' = \begin{pmatrix} 1 + \eta_1 & \frac{1}{2} \eta_6 & \frac{1}{2} \eta_5 \\ \frac{1}{2} \eta_6 & 1 + \eta_2 & \frac{1}{2} \eta_4 \\ \frac{1}{2} \eta_5 & \frac{1}{2} \eta_4 & 1 + \eta_3 \end{pmatrix} \mathbf{a}. $$ここで,
$ \eta_i $はガウス分布
$ \mathcal{N}\left( 0, \ \sigma_{\mathrm{st}}^2 \right) $から決まる値で,
$ \sigma_{\mathrm{st}} $は入力パラメーターsigma_stで指定できる(デフォルトはsigma_st = 0.5).
下の図に示すように,格子を変形させた後は,元の体積に戻す.
最後に最小原子間距離の制限をチェックする.

トーナメント選択
概要
トーナメント選択は,適応度に基づいて候補の中から親個体を選ぶための手法である.
この手法は,個体群内の選択圧と多様性のバランスをとるように設計されている.
下の図は,n_fittest = 10,t_size = 3の場合の例を示す.

手順
- 親個体候補から,所定の数(
t_size)の個体をランダムに選択 - その中で,最も適応度の高い(すなわち,エネルギーが最も低い)個体が親として選ばれる
- この処理を繰り返し,必要な数の親個体が選ばれるまで続ける
利点
- シンプルで効率的
- パラメータは1つだけ (
t_size) t_sizeを変えることで選択圧を調整可能
注意
t_sizeはデフォルトで3t_sizeが小さいと,多様性が促進されるt_sizeが大きいと,選択圧が増して,選択確率がより適応度に依存する- ルーレット選択とは異なり,トーナメント選択では下位の(
t_size- 1)個の個体が選択されることはない
ルーレット選択
概要
ルーレット選択は,適応度に基づいて親候補の個体の中から親個体を選ぶための確率的手法である. ルーレット選択においては,各個体の選ばれる確率はその適応度に比例する.
手順
fit_reverseがFalse(デフォルト)に設定されている場合,これはエネルギーを適応度として用いる最小化モードに対応しており,親候補の適応度には –1 が掛けられる.- 適応度
$ f_i $ は,以下の式により線形スケーリングされて
$ f'_i $ に変換される.ここで,
$ a $ および
$ b $ は,それぞれ
a_rltおよびb_rltで指定されるパラメータであり, $ a > b $ でなければならない.
$$ f_i' = \frac{a - b}{f_{\mathrm{max}} - f_{\mathrm{min}}} f_i + \frac{b f_{\mathrm{max}} - a f_{\mathrm{min}}}{f_{\mathrm{max}} - f_{\mathrm{min}}} $$ - スケーリング後の適応度
$ f'_i $ は,次式により選択確率に変換される:
$$ p_i = \frac{f_i'}{\sum_k f_k'} $$
各 $ p_i $ は, $ i $ 番目の個体が選ばれる確率を表す. - 親個体は, $ p_i $ に基づいてルーレット選択により1つずつ選ばれ,必要な数に達するまで繰り返される.
利点
- すべての個体が非ゼロの確率で選ばれる可能性がある
- 適応度のスケーリングによって選択圧を調整できる
注意
- デフォルトでは
a_rlt = 10.0,b_rlt = 1.0 - 意味のある選択圧を得るためには,適応度のスケーリングが重要である.
下の図は,
$ a $ が比較的小さい場合(左)と比較的大きい場合(右)における
$ p_i $ の例を示している.
$ a $ が小さすぎると選択圧が弱くなり,適応度の高い個体が優先されにくくなる.

組成可変型進化的アルゴリズム (EA-vc)
2025年7月7日 更新
概要
CrySPY 1.4.0 以降,組成固定型EAを拡張した組成可変型EA(EA-vc)が利用可能になった. サポートしているインターフェースはこちらを確認すること(インターフェース). 全体の流れは組成固定型EAと類似しているが,EA-vcでは異なる組成に対応するために,適応度の評価方法と子個体の生成方法が異なる. ここでは,元のEAから変更された部分について説明する.
バージョン1.4.1からは電荷中性条件を課した構造生成が可能になった.
手順
- 個体群(population)の初期化
- 適応度(fitness)の評価
- 自然選択
- 親個体の選択
- 次世代の生成
- ステップ2(適応度の評価)に戻り繰り返す
個体群(population)の初期化
第一世代では,n_pop で指定された数のランダム構造が生成される.
EAおよびEA-vcでは tot_struc は使用されない.
EA-vcでは,各原子種の原子数は,ユーザーが定義した範囲内でランダムに決定される.
各原子種ごとの原子数の最小値(ll_nat)および最大値(ul_nat)は,以下のように cryspy.in で指定することができる.
[structure]
atype = Cu Au
ll_nat = 0 0
ul_nat = 8 8
適応度(fitness)の評価
異なる原子数を持つ構造の全エネルギーを直接比較することには意味がないため,異なる組成間の相安定性を評価するために,形成エネルギーから計算された凸包(convex hull)が用いられる. 形成エネルギー,凸包,相図に関する情報はオンラインで参照できる. 例えば,Materials Project Documentation を参照のこと. EA-vcでは,適応度は energy above hull(hull distanceとも呼ばれる)として定義されている.

形成エネルギー
形成エネルギーは,基準となる安定な単体のエネルギー(eV/atom)に基づいて計算され,これらは cryspy.in の end_point で指定される.
例えば,Cu–Auの2元系の場合,end_point にはfcc-Cuおよびfcc-Auの1原子あたりのエネルギー(eV/atom)をこの順で記述する必要がある.
構造探索中に,end_point と同じ組成を持つ構造が見つかり,そのエネルギーが対応する end_point の値よりも低かったとしても,形成エネルギーの計算には依然として cryspy.in に定義された元の end_point の値が用いられることに注意すること.
凸包(Convex hull)
ある構造の形成エネルギーと,その組成におけるconvex hull上のエネルギーとの差は,energy above hull(hull distanceとも呼ばれる)と呼ばれる. この値は,同じ組成における最も安定な相の組み合わせと比べて,その構造の形成エネルギーがどれだけ高いかを示している. hull distanceが0の構造はconvex hull上にあり,熱力学的に安定である.
組成固定型EAとは異なり,EA-vcではconvex hullの計算時に構造の1原子あたりのエネルギーに基づいてフィルタリングを行い,以下の条件を用いる:
$$ \mathrm{emin\_ea} \le E \le \mathrm{emax\_ea} $$
このフィルタリングは形成エネルギーではなく,あくまで1原子あたりの全エネルギーに基づいて行われることに注意すること.
convex hullの計算には,pymatgen のPhaseDiagramクラスを使用している.
形成エネルギーの場合とは異なり,end_point と同じ組成を持つ構造が対応する end_point の値よりも低いエネルギーを持っていた場合,その構造がconvex hullおよびhull distanceを計算する際の基準として使用される.
自然選択
下図に示すように,EA-vcではhull distanceが0の安定構造が複数得られる場合がある.
このような場合,複数の個体がhull distanceにおいて同率の最上位ランクを占めることになる.
n_eliteで指定されたエリート構造の数が,同率ランクの個体数より少ない場合,選択には任意性が生じる.
現在のところ,CrySPYではhull distanceが0.001 eV/atom未満の個体の中から,n_elite 個をランダムに選択している.
hull distanceが 0.001 eV/atom未満の個体数が n_elite より少ない場合には,通常通り,適応度に基づくランキングによってエリート構造が選択される.
エリート個体を選択する際にも,pymatgen のStructureMatcherクラスを用いて重複構造を排除している.

エリート個体は,過去の世代で得られた最良の構造に基づいて選択される. しかし,hull distanceは世代ごとに変化する可能性があるため,自然選択を行う前に,現在のconvex hullを用いてエリート個体のhull distanceを再計算している.
Convex hullセクションで述べたように,EA-vcでは,emin_eaおよびemax_eaは自然選択では使用されない.
親個体の選択
親個体の選択方法は組成固定型EAと同様である.
次世代の生成
進化的操作
crossover(vc)の操作は,組成固定型EAのものとわずかに異なるが,permutationおよびstrainは同一である. EA-vcでは,組成可変にするためにいくつかの新しい操作が導入されている.
個体群の数
crossover,permutation,strain,addition,elimination,substitution,およびランダム生成による構造の合計は,n_pop と等しくなければならない.
n_pop=n_crsov+n_perm+n_strain+n_add+n_elim+n_subs+n_rand
組成可変型進化的アルゴリズム (EA-vc)のサブセクション
Crossover (vc)
組成可変型のcrossoverは,組成固定型のバージョンとほとんど同じであるが,原子数の調整が最小限に抑えられている点が異なる.
組成固定型crossoverのステップ6では,各原子種ごとの原子数の差を直接計算する.
一方,crossover(vc)では,ll_nat と ul_nat で定義された許容範囲に基づいて原子数の差を計算する.
例えば,次のようになる:
ll_nat = [4, 4, 4]
ul_nat = [8, 8, 8]
offspring_nat = [2, 6, 12]
nat_diff = [-2, 0, 4]
上記の例でいう nat_diff にあたる原子数の差が,許容値 nat_diff_tole を超えている場合は,この操作はやり直される.
そうでない場合は,原子数が ll_nat と ul_nat で定義された範囲に収まるように調整される.
Addition
2025年7月7日 更新
現在の原子数が ul_nat で指定された上限を超えない原子種をランダムに選択し,その原子をランダムな位置に1個追加する.
バージョン1.4.1からは複数の原子を追加する機能を搭載.追加する原子数はadd_max以下の自然数からランダムに選択される.
デフォルトではadd_max = 3.
- 原子を1個追加し,それが
mindistで指定される最小原子間距離の制限を満たしているかチェック. - 距離の条件を満たさない場合は,別のランダムな位置に再配置する.この処理は最大
maxcnt_ea回まで繰り返される. - (since version 1.4.1) ランダムに決められた原子数(
add_max以下)が追加されるまで繰り返す. - 有効な子個体が得られなければ,体積を10%拡張して,同じ処理を最大
maxcnt_ea回まで再試行する. - それでも失敗した場合は,体積を最大20%まで拡張して構造生成を試みる.それでもうまくいかない場合は,親個体を変更する.

Elimination
2025年7月7日 更新
現在の原子数が ll_nat で指定された下限を上回っている原子種をランダムに選択し,その原子を1個削除する.
バージョン1.4.1からは複数の原子を削除する機能を搭載.削除する原子数はelim_max以下の自然数からランダムに選択される.
デフォルトではelim_max = 3.

Substitution
2025年7月7日 更新
Substitutionは,2つの異なる原子種をランダムに選択し,位置を入れ替える操作である.
バージョン1.4.1からは複数の原子を入れ替える機能を搭載.入れ替える原子数はsubs_max以下の自然数からランダムに選択される.
デフォルトではsubs_max = 3.
- 入れ替え後の構造の原子数が最小原子数(
ll_nat)と最大原子数(ul_nat)を超えないように制限. - 最終的に,
mindistで指定される最小原子間距離の制限をチェックし,問題がなければその構造を子個体として採用する.

Bayesian optimizaion (BO)
under construction
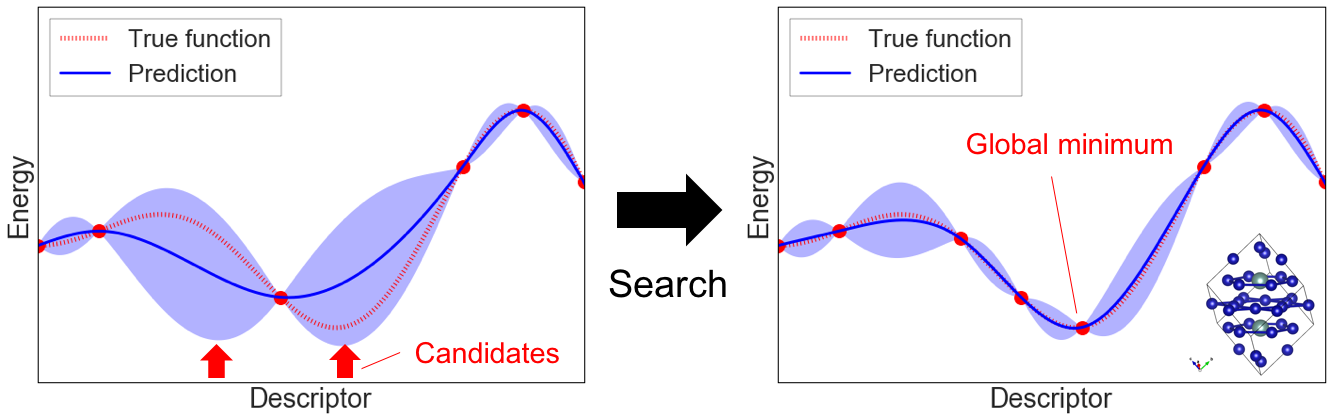
One of the selection-type algorithms.
Reference
LAQA
選択型アルゴリズムの一つ.
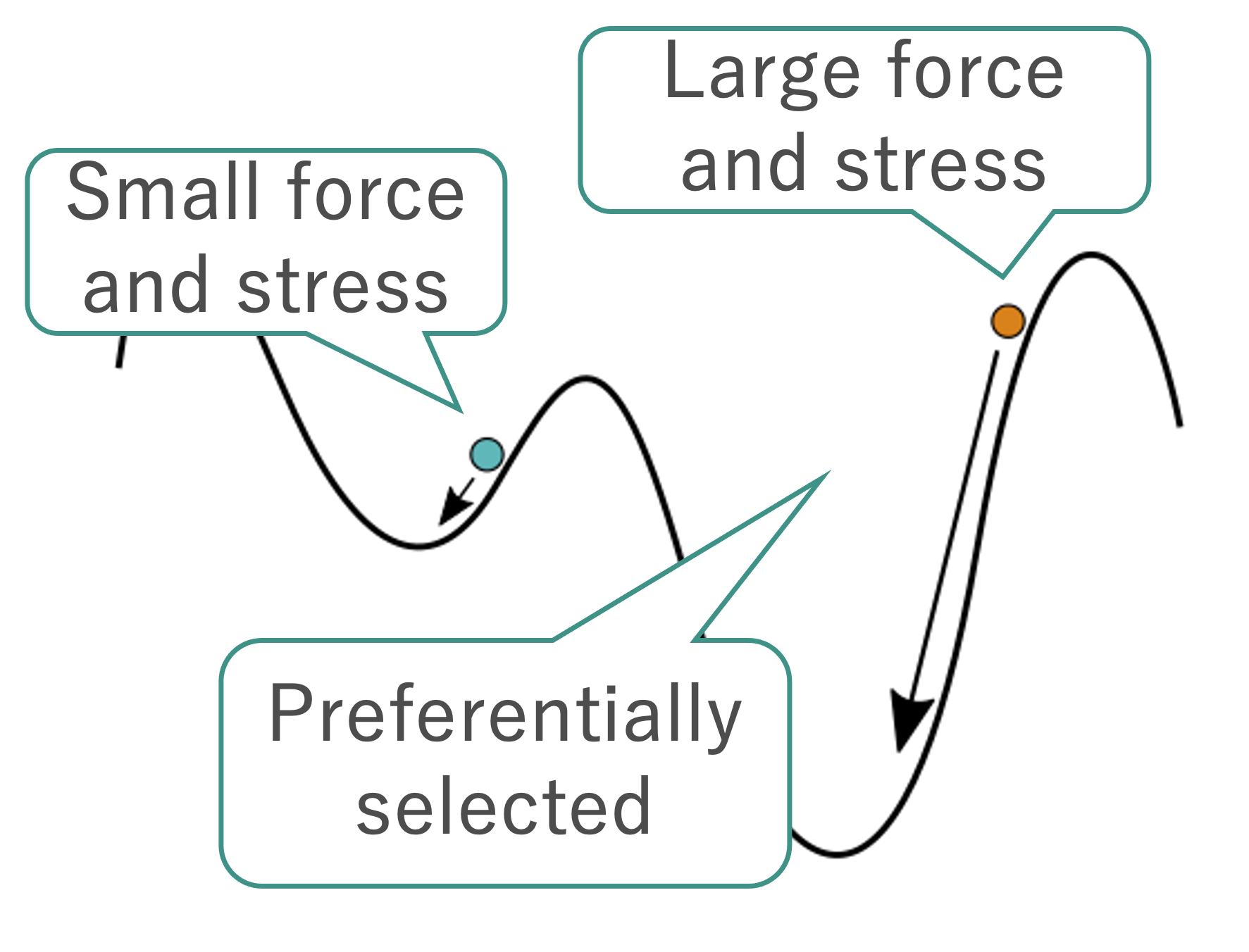
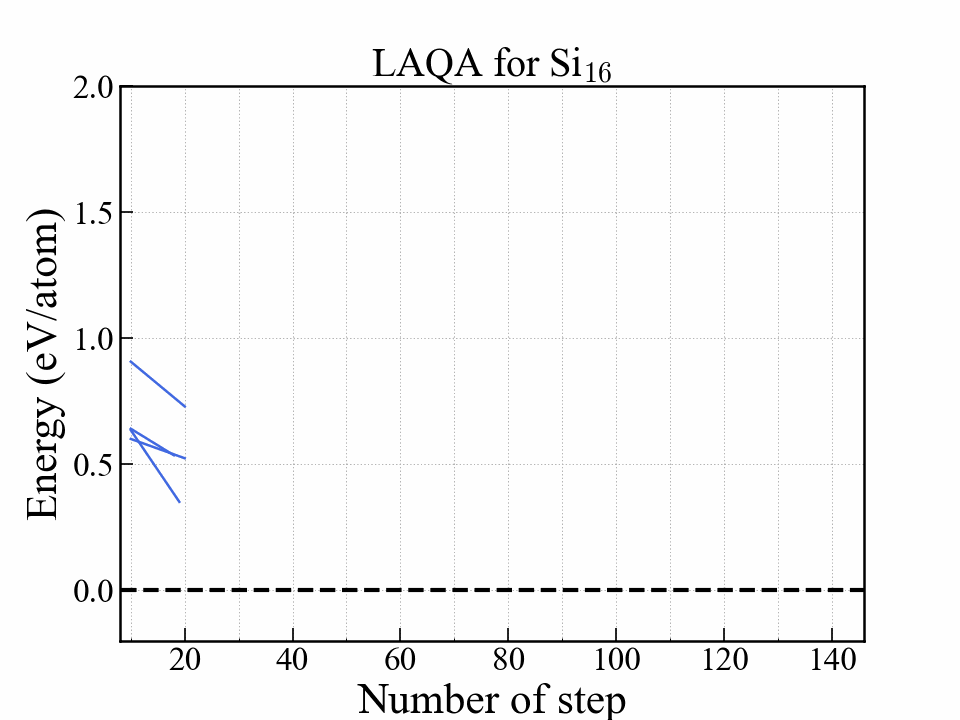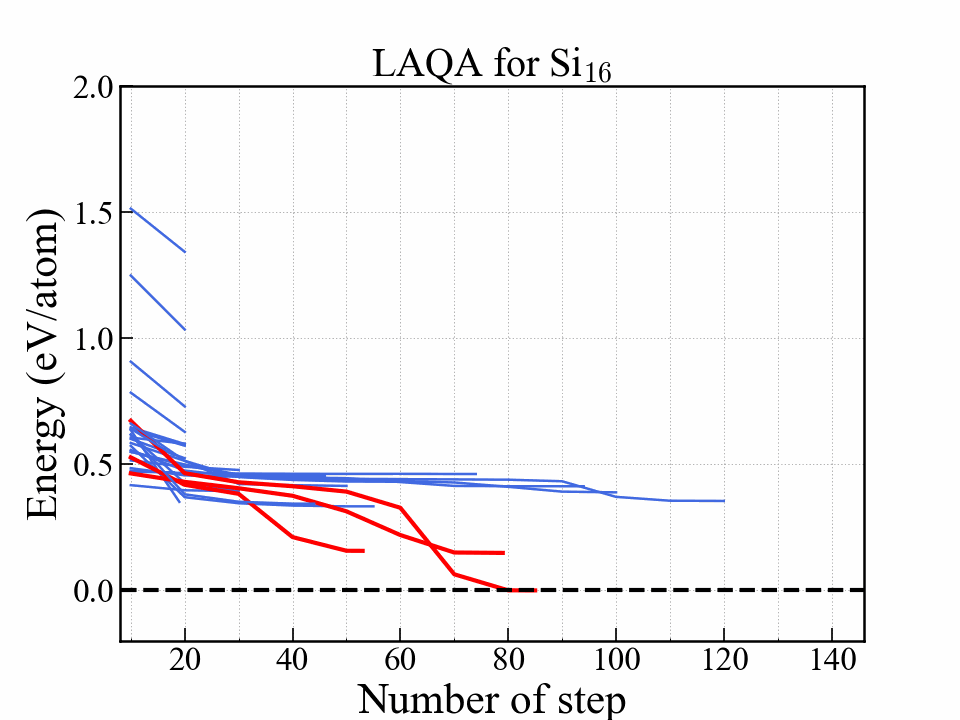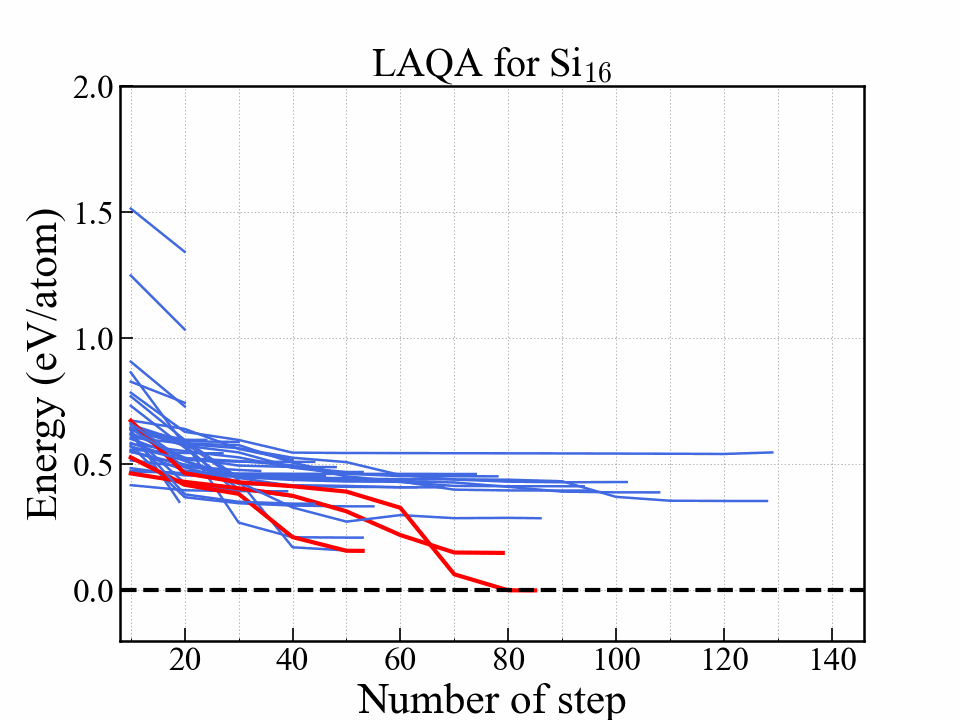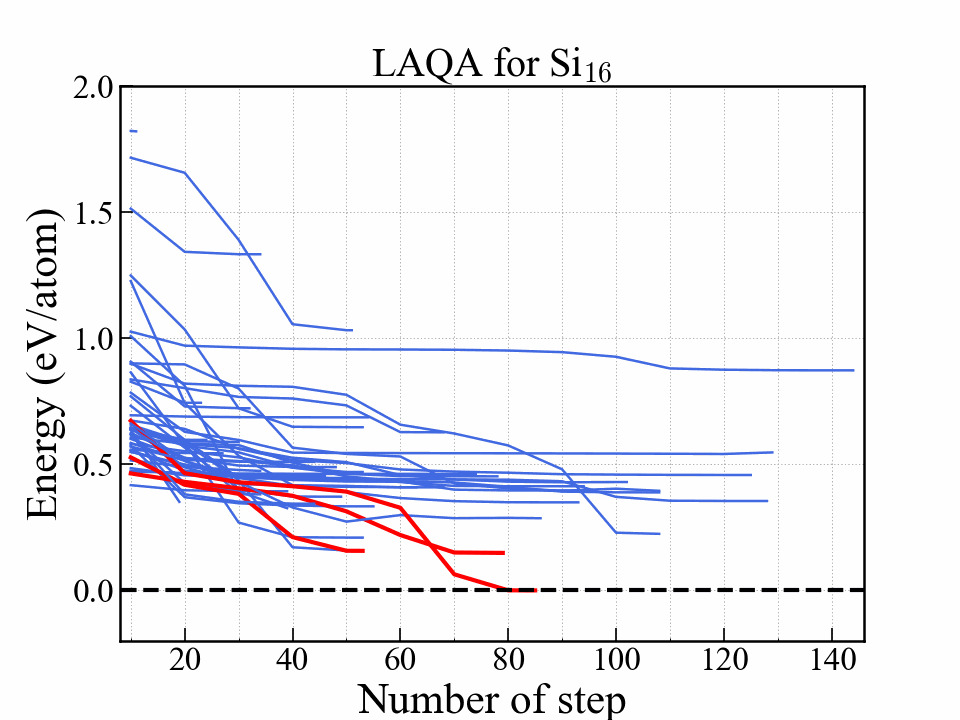
Score $ L $
$$ L = -E + w_F \frac{F^2}{2\Delta F} + w_S S. $$| Symbol | Note |
|---|---|
| $$ E $$ | エネルギー(eV/atom) |
| $$ w_F $$ | 力の項の重み. Default: $ w_F = 0.1$ |
| $$ F $$ | 原子に働く力の平均ノルム(eV/Å) |
| $$ \Delta F $$ | 一つ前のステップからの $ F $の差の絶対値.はじめのステップでは $ \Delta F = 1$. $ \Delta F = 10^{-6}$ if $ \Delta F \le 10^{-6} $. |
| $$ w_S $$ | ストレス項の重み.Default: $ w_S = 10.0$ |
| $$ S $$ | ストレステンソルにおける成分の絶対値平均(eV/Å^3). |